Previsione della manutenzione dei macchinari con Python e il Machine learning
- Team I.A. Italia

- 21 apr 2022
- Tempo di lettura: 2 min
Previsione della manutenzione dei macchinare con il Machine Learning.

Sappiamo che l'apprendimento automatico è molto complicato per i principianti. Non sappiamo quali tipi di modelli dovremmo usare per analizzare i dati.
In questo articolo, utilizzeremo il set di dati "Manutenzione predittiva" e lo analizzeremo utilizzando facilmente l'apprendimento automatico. Useremo Pycaret per costruire il nostro modello predittivo. Questo è il set di dati che useremo:
Prima di iniziare, installa Pycaret sui tuoi ambienti notebook.
pip install pycaret Importazione di librerie di importazione
Successivamente, dobbiamo importare le librerie. Dopo averlo fatto, leggiamo il file di dati che analizzeremo. Il file è in formato .csv.
import pandas as pd
import seaborn as sns
%matplotlib inline
import matplotlib.pyplot as plt
data = pd.read_csv("Manutenzione_macchinari.csv")
Creiamo un grafico a torta usando Matplotlib per il tipo di errore. Abbiamo notato che nessun errore è del 96,5%.
labels = data['Failure Type'].astype('category').cat.categories.tolist()
counts = data['Failure Type'].value_counts()
sizes = [counts[machine_name] for machine_name in labels]
plt.figure(figsize=(8,10))
plt.pie(sizes, labels=labels, autopct='%1.1f%%',shadow=True)
plt.title("Failure Type", fontsize=20)
plt.show()

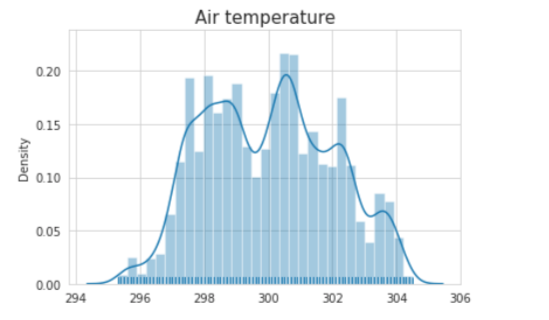
Successivamente, utilizziamo la libreria "Seaborn" per creare un grafico a barre per la temperatura dell'aria e di processo.
# Air Temperature #
sns.set_style('whitegrid')
sns.distplot(data['Air temperature [K]'].values, kde=True, rug=True)
plt.title("Air temperature",fontsize = 15)
plt.show()
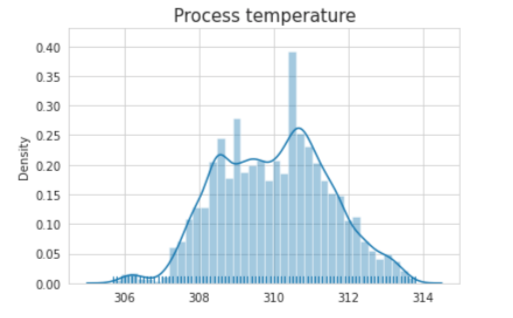
#Process Temperature #
sns.distplot(data['Process temperature [K]'].values, kde=True, rug = True )
plt.title("Process temperature",fontsize=15)
plt.show()

Dopo averlo fatto, utilizziamo jointplot per disegnare un grafico dell'aria e della temperatura di processo con grafici bivariati e univariati. La libreria fornisce una comoda interfaccia per la classe JointCrid, con diversi tipi di grafici preconfezionati. Sembrano così.
with sns.axes_style('white') :
g = sns.jointplot(data=data,x='Air temperature [K]',y= 'Process temperature [K]', kind = "hex",joint_kws = dict(gridsize=15),
marginal_kws={'color': 'gold'},color="#c9af44", height = 6.50)
plt.setp(g.ax_marg_y.patches, color = "limegreen")
Usiamo Seaborn per disegnare un grafico a linee per la velocità della coppia perché vogliamo conoscere la sua velocità di rotazione.
plt.figure (figsize = (8,6))
sns.lineplot(x="Rotational speed [rpm]", y="Torque [Nm]",data=data)
plt.title ("Speed of Torque ", fontsize = 15)
In questo momento, utilizzeremo la libreria unica "PyCaret". È una libreria di machine learning open source in Python che consente agli utenti di passare dalla preparazione dei dati alla distribuzione del modello in pochi minuti negli ambienti notebook scelti.
PyCaret
Prima di utilizzare PyCaret, è necessario eliminare l'UDI e l'ID prodotto del set di dati.
data = data.drop(['UDI','Product ID'],axis=1)
Usiamo 'pycaret.classification' per impostare con set di dati, target e session_id originali. Dopo averlo fatto, confrontiamo tutti i modelli. Abbiamo notato che il modello Random Forest ha la massima precisione. Allora usiamolo.
from pycaret.classification import *
#Setup#
pyrg = setup (data,target='Failure Type',session_id = 1)
#Compare any models"
rf = compare_models()
Creiamo un modello con rf (Random Forest Classifier). Inoltre, dobbiamo migliorarlo con tune_model. È una funzione che sintonizza automaticamente il modello con gli iperparametri.

Dopo averlo realizzato, creiamo grafici per l'analisi del modello.
plot_model(rf)
plot_model(estimator = rf, plot = 'feature')
plot_model(rf, plot = 'confusion_matrix')
Abbiamo quasi finito! Finalizziamo il modello e lo prevediamo con il set di dati originale. Leggiamo il dataset finale. Come possiamo vedere, ha aggiunto etichette e punteggi.
rf_final = finalize_model(rf)
predict_rf = predict_model(rf_final,data)
predict_rf.head()
Conclusione
In questo articolo, abbiamo imparato come analizzare facilmente un set di dati utilizzando l'apprendimento automatico. È meglio usare questo metodo se non conosci gli algoritmi di machine learning.






.png)

Commenti