Machine learning con excel
- Team I.A. Italia

- 12 set 2022
- Tempo di lettura: 16 min
Tranquilli non siamo impazziti 🤣 nel blog post di oggi andiamo a vedere come applicare il machine sui tuoi dati utilizzando direttamente excel.
Alla fine di questo tutorial, avrai implementato il tuo primo algoritmo senza scrivere una singola riga di codice. Utilizzerai le tecniche di Machine Learning per classificare i dati reali utilizzando le funzioni di base in Excel. Non devi essere un genio o un programmatore per capire l'apprendimento automatico. Nonostante le applicazioni popolari di auto a guida autonoma, robot killer e riconoscimento facciale, le basi dell'apprendimento automatico (ML) sono abbastanza semplici. Questa è un'occasione per bagnare i piedi e comprendere la potenza di queste nuove tecniche.
Prima di iniziare chiediamo scusa a tutti i data scientist che leggeranno questo articolo🙌
Cosa ne pensiamo NOI del Machine learning con excel
Tutti i data scientist probabilmente stanno rabbrividendo al titolo di questo tutorial. Excel è generalmente considerato uno strumento terribile per l'analisi dei dati seria. Non è scalabile per elaborare i grandi set di dati con cui abbiamo a che fare nel mondo reale e manca di alcune funzionalità chiave dei linguaggi di programmazione e delle librerie di apprendimento automatico.
Vedrai che molte delle formule fornite in questo tutorial sono complicate da capire per le carenze e le peculiarità di Excel. Il motivo per cui sto usando Excel è rendere questa introduzione accessibile ai non programmatori poiché la maggior parte di noi ha una conoscenza di base dello strumento. Coloro che scelgono di perseguire più seriamente l'apprendimento automatico e la scienza dei dati alla fine passeranno all'utilizzo di Python o R, ma non c'è nulla di male nell'iniziare in modo semplice.

Machine learning con excel : Il nostro obiettivo finale
L'obiettivo finale di questo tutorial è utilizzare Machine Learning per costruire un modello di classificazione su un insieme di dati reali utilizzando un'implementazione dell'algoritmo k-nearest neighbors (KNN). Non lasciarti sopraffare, analizziamo poco a poco cosa significa.
Apprendimento automatico
Machine Learning è una raccolta di tecniche per creare o ottimizzare i modelli. In altre parole, Machine Learning prende i modelli che abbiamo costruito e usa i dati del mondo reale per "imparare" come mettere a punto i parametri del modello per essere più utili in uno scenario del mondo reale basato sui dati di addestramento.
In questo tutorial applicheremo l'apprendimento automatico a un modello di classificazione. Non preoccuparti se non sei del tutto chiaro in questo momento, alla fine del tutorial saprai esattamente di cosa sto parlando.
Set di allenamento vs set di prova
Gli algoritmi di Machine Learning adattano il modello in base a una serie di dati di addestramento. I dati di allenamento sono un set di dati che contiene tutte le variabili che abbiamo a disposizione e la corretta classificazione. I set di allenamento possono essere sviluppati in vari modi, ma in questo tutorial utilizzeremo un set di allenamento classificato da un esperto umano. È importante ricordare che i modelli di apprendimento automatico sono validi solo quanto i dati di addestramento. Più sono accurati i tuoi dati di allenamento e più ne hai, meglio è. In altre parole: spazzatura dentro, spazzatura fuori.
Un set di test è in genere un sottoinsieme dei dati di addestramento in quanto contiene anche tutte le variabili e le classificazioni corrette. La differenza sta nel modo in cui lo usiamo. Mentre il set di allenamento aiuta a sviluppare il modello, il set di test lo prova in uno scenario reale e vede come se la cava bene. Esistono molti modi complicati per misurare gli errori e testare i modelli, ma finché ottieni l'idea di base possiamo andare avanti.
Machine learning con excel : Modelli di classificazione
Un modello di classificazione è semplicemente uno strumento matematico per determinare quale categoria o classe di qualcosa hai a che fare in base a un insieme di variabili o input. Ad esempio, se volessi classificare se un animale è un gatto o un pesce, potrei usare variabili come se l'animale nuota o meno, se ha o meno la pelliccia e se mangia o meno per determinare quale classe appartiene sotto. Noterai due cose. In primo luogo, più variabili hai, meglio è.
Con ulteriori informazioni, puoi essere più sicuro che la tua classificazione sia corretta. In secondo luogo, alcune variabili sono più utili o predittivedi altri. Prendi l'ultimo esempio, indipendentemente dal fatto che l'animale mangi o meno. L'osservatore casuale sa che sia i pesci che i gatti mangiano, quindi avere questo dato non è utile per determinare la classe dell'animale. L'obiettivo del machine learning in questo contesto è quello di creare il modello di classificazione più utile dati i dati disponibili e di eliminare gli input che non migliorano l'efficacia del modello.
Machine learning con excel : K-Nearest Neighbors
K-Nearest Neighbors (KNN) è un tipo specifico di modello di classificazione. L'intuizione è semplice da capire. Il modello prende tutti i dati disponibili su un punto dati sconosciuto e li confronta con un set di dati di addestramento per determinare a quali punti in quel set di addestramento il punto sconosciuto è più simile o più vicino. L'idea è che il punto dati sconosciuto molto probabilmente rientrerà nella stessa classe dei punti dati noti a cui è più simile. KNN è semplicemente un modo matematico per determinare la somiglianza tra due punti dati.
Il set di dati dell'iris
Per questo tutorial utilizzeremo un set di dati classico utilizzato per insegnare l'apprendimento automatico chiamato Iris Data Set . Questa è una raccolta di dati su tre specie di fiori di Iris e quattro dati su di esse: lunghezza del sepalo, larghezza del sepalo, lunghezza del petalo e larghezza del petalo. Il set di dati è già stato preparato per facilitare l'accesso ai principianti. Puoi scaricare i dati in un formato excel compatibile a questo link facendo clic su "scarica zip" in alto a destra e aprendo i contenuti in Excel.
Machine learning con excel : Preparare i nostri dati
Come ho già detto, questo set di dati è pensato per essere semplice da utilizzare. Ognuna delle prime 4 colonne (AD) è una dimensione, o caratteristica, dei dati. La quinta colonna, E, è la varietà o la classe del fiore. Ogni riga è il proprio record o punto dati. Come puoi vedere, abbiamo 150 punti dati noti con cui lavorare.
Abbiamo una decisione importante da prendere: come vogliamo segregare questo set di dati in un set di addestramento e un set di test. Dato un set di dati più grande, ci sono tecniche di ottimizzazione che potremmo usare per prendere questa decisione. Poiché questo set di dati è piccolo e pensato per i principianti, lo divideremo 70/30 per convenzione. In altre parole, utilizzeremo il 70% dei dati, ovvero 105 punti dati come set di addestramento e i restanti 45 punti dati come set di test.
Ora useremo Excel per campionare casualmente il 70% dei dati. Innanzitutto, aggiungi una colonna al tuo foglio chiamata "Valore casuale" e usa la funzione RAND() per selezionare casualmente un valore compreso tra 0 e 1. Tieni presente che la funzione RAND() riseleziona un nuovo numero ogni volta che il tuo foglio ricalcola. Per evitarlo, dopo aver generato i miei numeri li copierò (Ctrl+C) e poi li incollerò in modo speciale come valori (Ctrl+Shift+V) in modo che rimangano fissi. Inizieremo nella cella F2 e trascineremo fino all'ultimo punto dati.
=RAND()Successivamente li classificherò da 1 a 150 utilizzando la funzione RANK() di Excel, iniziando nella cella G2 come mostrato di seguito e trascinando fino all'ultimo punto dati. Assicurati di bloccare il quadro di riferimento come mostrato premendo F4 o aggiungendo manualmente i segni $, altrimenti questa formula non funzionerà come previsto.
=RANGO(F2, $F$2:$F$15)Ora abbiamo un valore univoco compreso tra 1 e 150 per ciascun punto dati. Poiché vogliamo 105 valori per il nostro set di allenamento, aggiungeremo un'altra colonna e selezionare i valori classificati da 1 a 105 per il nostro set di allenamento utilizzando una funzione IF() rapida. In caso contrario, aggiungeremo il valore al nostro set di test. Di nuovo, inizieremo da H2 e trascineremo fino all'ultimo punto dati.
=SE(G2<=105,”Train”, “Test”)A questo punto il tuo set di dati dovrebbe essere impostato come lo screenshot. Ricorda che poiché ognuno di noi ha preso un campione casuale diverso, i valori specifici nelle colonne FH avranno un aspetto diverso per te. Dovresti anche dedicare un minuto all'aggiunta di filtri per il nostro passaggio successivo.

Successivamente suddivideremo i nostri due set di dati nei loro fogli di lavoro (o schede) per mantenere le cose organizzate. Crea un nuovo foglio di lavoro chiamato "Training Set" e filtra i dati "Training" nel foglio di lavoro originale. Copia questi dati insieme alle intestazioni e incollali nel tuo "Training Set". Dovresti avere 106 righe (105 valori + la riga di intestazione). Fai lo stesso per il foglio di lavoro "Set di test". Dovresti avere 46 righe (45 valori + la riga di intestazione).
A questo punto puoi eliminare il foglio di lavoro "Iris" ed eliminare le colonne FH in entrambi i fogli di lavoro rimanenti poiché abbiamo già separato i nostri dati. Infine, aggiungerò una colonna "ID" all'inizio di ogni foglio di lavoro ed etichetterò ciascun punto dati rispettivamente 1–105 e 1–45 semplicemente digitando il numero (trascinando verso il basso il quadratino di riempimento sarà tuo amico qui per salvarti il lavoro ). Questo ci aiuterà a fare i nostri calcoli nelle prossime sezioni. Assicurati che ciascuno dei tuoi set sia organizzato come nell'esempio seguente.

Machine learning con excel : Costruire il modello
I nostri dati sono ora pronti e possiamo procedere alla costruzione del nostro modello. Come promemoria, questo modello funziona confrontando il punto dati sconosciuto che desideriamo classificare con i suoi k più vicini o più simili. Per fare ciò dovremo prendere ogni punto nel nostro set di test e calcolare la sua distanza da ciascun punto nel set di allenamento.
per k intendiamo "oggetti o istanze" dello stesso tipo
Machine learning con excel : Il concetto di distanza

La distanza è il modo in cui i matematici determinano quali punti sono più simili in uno spazio n-dimensionale. L'intuizione è che più piccola è la distanza tra i punti più sono simili. La maggior parte di noi è abituata a calcolare la distanza in uno spazio bidimensionale, come un sistema di coordinate x,y, o usando longitudine e latitudine. Esistono diversi modi per calcolare la distanza, ma per semplificare utilizzeremo la distanza euclidea. Di seguito è riportata una visualizzazione della formula della distanza euclidea in uno spazio bidimensionale.
Come puoi vedere, la formula funziona creando un triangolo rettangolo tra due punti e determinando la lunghezza dell'ipotenusa, il lato più lungo del triangolo, come identificato dalla freccia.
Il nostro set di dati è a 4 dimensioni. È difficile per noi visualizzare spazi oltre le 3 dimensioni, ma indipendentemente dal fatto che tu possa visualizzarlo o meno possiamo comunque calcolare la distanza tra due punti allo stesso modo indipendentemente dal numero di dimensioni. Ecco la formula generica per la distanza euclidea:

In parole povere questo sta dicendo è che la distanza euclidea tra due punti, q & p, può essere determinata prendendo ogni dimensione per ogni punto, a partire dalla prima dimensione, e quadrando la differenza tra loro in modo iterativo finché non lo hai fatto per tutte le dimensioni e sommate le differenze. Quindi prendiamo la radice quadrata di quella somma e abbiamo la distanza euclidea. Sembra complicato ma vedrai che in realtà è abbastanza semplice da usare una volta che torniamo nei nostri dati.
Machine learning con excel : Calcolo della distanza
Nella nostra cartella di lavoro, crea un nuovo foglio di lavoro chiamato "Distanza". Il nostro obiettivo per questo foglio è creare una matrice 45X105 delle distanze tra ciascun punto dati nel set di test e il set di allenamento. Nel nostro caso, ogni riga corrisponderà a un punto dati nel set di test e ogni colonna corrisponderà a un punto dati nel set di addestramento. Partendo da A2 e procedendo riga per riga fino a raggiungere A46, riempi ogni cella con i numeri 1–45. Anche in questo caso, il quadratino di riempimento è utile qui, quindi non è necessario digitare i numeri uno per uno. Ora, lavorando da B1 e poi colonna per colonna orizzontalmente fino a quando non colpisci DB1, riempi ogni colonna con i numeri 1–105. La tua matrice dovrebbe assomigliare allo screenshot qui sotto che ne mostra una piccola parte.

Prima di andare avanti, dovrai convertire la tua matrice in una tabella in modo da poter mantenere le cose organizzate. Seleziona l'intera matrice e premi Ctrl+T, quindi nomina la tabella "Distance_Table" e seleziona per creare la tabella con le intestazioni. Successivamente, ti consigliamo di nominare la tua prima colonna "ID test" digitandolo nella cella A1.
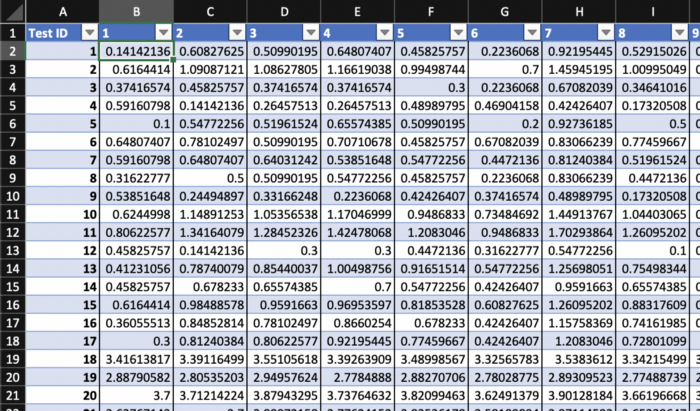
Ora che la nostra tabella è impostata possiamo iniziare i nostri calcoli. Inizieremo nella cella B2 che calcolerà la distanza tra il primo punto nel nostro Training Set (ID #1) e il primo punto nel nostro Test Set (ID #1). Possiamo applicare rapidamente la formula della distanza euclidea utilizzando la funzione CERCA.VERT in Excel per trovare i valori per ciascuna dimensione e quindi eseguire i calcoli secondo necessità. È meglio copiare e incollare questa formula nella barra della formula nella cella B2 poiché gestisce un paio di particolarità della funzione Tabella in Excel, ma assicurati di capire che tutto ciò che questa formula sta facendo è applicare la formula Distanza euclidea di cui abbiamo discusso in precedenza. Come scritto, puoi quindi trascinarlo per riempire l'intera tabella.
=SQRT(((VLOOKUP(NUMBERVALUE(Distance_Table[[#Headers],[1]]), ‘Training Set’!$A$1:$F$106, 2, FALSE)-VLOOKUP(Distance_Table[@[Test ID]:[Test ID]], ‘Test Set’!$A$1:$F$46, 2, FALSE)) ^ 2+(VLOOKUP(NUMBERVALUE(Distance_Table[[#Headers],[1]]), ‘Training Set’!$A$1:$F$106, 3, FALSE)-VLOOKUP(Distance_Table[@[Test ID]:[Test ID]], ‘Test Set’!$A$1:$F$46, 3, FALSE)) ^ 2+(VLOOKUP(NUMBERVALUE(Distance_Table[[#Headers],[1]]), ‘Training Set’!$A$1:$F$106, 4, FALSE)-VLOOKUP(Distance_Table[@[Test ID]:[Test ID]], ‘Test Set’!$A$1:$F$46, 4, FALSE)) ^ 2+(VLOOKUP(NUMBERVALUE(Distance_Table[[#Headers],[1]]), ‘Training Set’!$A$1:$F$106, 5, FALSE)-VLOOKUP(Distance_Table[@[Test ID]:[Test ID]], ‘Test Set’!$A$1:$F$46, 5, FALSE)) ^ 2))Dovresti finire con qualcosa del genere:
Machine learning con excel : Trovare i K più vicini
A questo punto abbiamo calcolato la distanza tra ogni punto del nostro set di test e ogni punto del nostro set di allenamento. Ora dobbiamo identificare i k più vicini a ciascun punto nel nostro set di test. Crea un nuovo foglio di lavoro chiamato "k più vicini" e iniziando da A2 lavora riga per riga per riempire le celle con i numeri 1–45 in modo che corrispondano ai punti nel nostro set di test. Le nostre colonne non rappresenteranno il Training Set come nei fogli precedenti. Invece, questi rappresenteranno i 6 k più vicini, iniziando con il primo più vicino e poi il secondo più vicino e così via. Il primo vicino più vicino ha la distanza più piccola, il secondo vicino più vicino ha la seconda distanza più piccola e così via. Il tuo foglio dovrebbe assomigliare a questo:

Come abbiamo già fatto, scriveremo una formula nella cella B2 che può essere trascinata per riempire il resto della nostra matrice. Il nostro approccio consiste nell'identificare il valore più piccolo nella riga corrispondente (2) nella tabella delle distanze, trovare il numero di colonna per quel valore e quindi restituire il nome della colonna poiché questo ci darà l'ID del valore nel Training Set. Utilizzeremo una combinazione delle funzioni Indice e Match per raggiungere questo obiettivo. Nota che siamo in grado di semplificare questa formula perché abbiamo avuto la lungimiranza di impostare la nostra matrice Distanza come tabella in Excel e quindi possiamo facilmente inserire le intestazioni.
=INDEX(Distance_Table[#Headers], MATCH(SMALL(Distance!$B2:$DB2, 1), Distance!2:2, FALSE))Trascina questa formula per riempire la riga superiore della matrice dei tuoi k più vicini. Dovrai regolare manualmente il valore in grassetto nella funzione SMALL() per rappresentare il vicino che stiamo cercando. Quindi, ad esempio, per trovare il secondo vicino più vicino la formula sarebbe la seguente.
=INDEX(Distance_Table[#Headers], MATCH(SMALL(Distance!$B2:$DB2, 2), Distance!2:2, FALSE))Ricorda che i tuoi valori saranno diversi poiché il tuo campione casuale utilizzato per formare il set di test è diverso dal mio.

A questo punto, di solito mi prendo un minuto per ricontrollare manualmente una delle righe quando possibile solo per assicurarmi che le mie formule funzionino come previsto. Su larga scala ti consigliamo di utilizzare i test automatizzati, ma per ora lo stiamo semplificando.
Abbiamo un ultimo passaggio: dobbiamo identificare la classificazione di ciascuno dei nostri vicini più prossimi. Torneremo alla formula in B2 e la modificheremo per eseguire un VLOOKUP dell'ID nel Training Set e restituire la classifica. Lo trascineremo quindi per riempire la matrice.
=VLOOKUP(NUMBERVALUE(INDEX(Distance_Table[#Headers], MATCH(SMALL(Distance!$B2:$DB2, 1), Distance!2:2, FALSE))), ‘Training Set’!$A$1:$F$106, 6, FALSE)Fare un passo indietro
Facciamo un passo indietro e guardiamo cosa abbiamo realizzato. Ora hai identificato per ogni punto nel tuo test impostato la classificazione per i 6 k più vicini. Probabilmente noterai che per tutti o quasi tutti i tuoi punti dati i 6 k più vicini rientreranno tutti nella stessa classificazione. Ciò significa che il nostro set di dati è altamente raggruppato. Nel nostro caso, i nostri dati sono altamente raggruppati per due motivi. In primo luogo, come discusso all'inizio del tutorial, il set di dati è progettato per essere facile da usare. In secondo luogo, questo è un set di dati a bassa dimensione poiché stiamo lavorando solo con 4 dimensioni. Man mano che gestisci i dati del mondo reale, scoprirai in genere che sono molto meno raggruppati, soprattutto all'aumentare del numero di dimensioni. Minore è il raggruppamento dei dati, maggiore dovrà essere il training set per creare un modello utile.
Ottimizzazione con l'apprendimento automatico
Se i nostri dati fossero sempre raggruppati in modo ordinato come il set di dati Iris, non ci sarebbe bisogno dell'apprendimento automatico. Troveremmo semplicemente il vicino più vicino usando la nostra formula e la useremmo per determinare la classificazione di ogni punto dati sconosciuto. Poiché di solito non è così, l'apprendimento automatico ci aiuta a prevedere con maggiore precisione la classificazione di un punto dati sconosciuto osservando più vicini contemporaneamente. Ma quanti vicini dobbiamo guardare? È qui che entra in gioco la "K" in K-Nearest Neighbors. K descrive il numero di vicini che prenderemo in considerazione quando prevediamo la classificazione di un punto dati sconosciuto. Troppi pochi o troppi vicini
Intuitivamente, è importante capire perché questo problema è complicato. È possibile guardare troppo pochi vicini e anche troppi vicini. Soprattutto con l'aumento del numero di dimensioni, è possibile che il vicino più vicino non sia sempre la classificazione corretta. Guardare troppo pochi vicini limita la quantità di informazioni che il tuo modello ha a disposizione per fare la sua determinazione. Considerare troppi vicini degraderà effettivamente la qualità delle informazioni utilizzate dal tuo modello come input. Questo perché man mano che vengono introdotti più vicini, si introduce anche rumore nei dati. Pensaci: non avrebbe senso considerare tutti i 104 vicini nel nostro esempio! Vedere una rappresentazione visiva di questo concetto di seguito.

Quindi questo diventa un classico problema di ottimizzazione in cui tentiamo di trovare il valore K che fornisce la maggior parte delle informazioni senza essere troppo alto o troppo basso.
Usiamo il tuo set di prova
Per questo tutorial, utilizzeremo un processo molto semplice di tentativi ed errori per determinare il valore K ottimale. Prima di andare avanti, ti consiglio di guardare il foglio di lavoro k più vicini e di fare un'ipotesi su quale potrebbe essere il miglior valore k, solo per divertimento. Lo scopriremo presto se hai ragione!
Machine Learning con Excel : Impostazione dell'algoritmo
Un algoritmo è solo un insieme di passaggi che un computer deve ripetere più e più volte secondo un insieme definito di regole. In questo caso, diremo al computer di provare diversi valori K, calcoleremo il tasso di errore per ciascuno utilizzando il nostro set di test e quindi alla fine restituiremo il valore che produce il tasso di errore più basso. Per fare ciò dovremo creare un nuovo foglio di lavoro chiamato "Modello KNN". Lo configureremo come segue, etichettando le righe da A4 a A48 con 1–45 per ciascuno dei nostri punti dati di test.

Iniziamo con il valore previsto nella colonna B. Abbiamo bisogno che questa formula si aggiusti in base al valore K. Nel caso in cui il valore K sia 1, la formula è semplice, prendiamo solo il vicino più vicino.
=’Nearest Neighbors’!B2Nel caso in cui il valore K sia maggiore di 1, prenderemo il vicino più comune che appare. Se l'occorrenza dei vicini è equamente distribuita, ad esempio se 3 dei vicini sono Setosa e 3 dei vicini sono Virginica quando K=6, ci si schiererà con la classificazione del vicino più prossimo. La formula per K=2 sarebbe la seguente. Usiamo IFERROR perché questa formula restituisce un errore quando ci sono due vicini che si verificano un numero uguale di volte per il valore K dato.
=IFERROR(INDEX(‘Nearest Neighbors’!B2:C2,MODE(MATCH(‘Nearest Neighbors’!B2:C2,’Nearest Neighbors’!B2:C2,0))), ‘Nearest Neighbors’!B2)Ti consigliamo di utilizzare la formula espansa di seguito nella cella B4 che ti consente di utilizzare valori K fino a K = 6 incluso. Non c'è bisogno di preoccuparsi delle specifiche di questa formula, basta copiarla e incollarla. A proposito, dover usare formule complicate, schizzinose e difficili da capire come queste sono uno dei limiti di Excel a cui mi riferivo in precedenza. Questo sarebbe stato un gioco da ragazzi in Python. Nota che questa formula restituirà un errore se non c'è un valore in K o un valore non compreso tra 1 e 6. Dovresti copiare questa formula dalla cella B4 alla colonna B.
=IFS($B$1=1, 'Nearest Neighbors'!B2, $B$1=2, IFERROR(INDEX('Nearest Neighbors'!B2:C2,MODE(MATCH('Nearest Neighbors'!B2:C2,'Nearest Neighbors'!B2:C2,0))), 'Nearest Neighbors'!B2), $B$1=3, IFERROR(INDEX('Nearest Neighbors'!B2:D2,MODE(MATCH('Nearest Neighbors'!B2:D2,'Nearest Neighbors'!B2:D2,0))), 'Nearest Neighbors'!B2), $B$1=4, IFERROR(INDEX('Nearest Neighbors'!B2:E2,MODE(MATCH('Nearest Neighbors'!B2:E2,'Nearest Neighbors'!B2:E2,0))), 'Nearest Neighbors'!B2), $B$1=5, IFERROR(INDEX('Nearest Neighbors'!B2:F2,MODE(MATCH('Nearest Neighbors'!B2:F2,'Nearest Neighbors'!B2:F2,0))), 'Nearest Neighbors'!B2),$B$1=6, IFERROR(INDEX('Nearest Neighbors'!B2:G2,MODE(MATCH('Nearest Neighbors'!B2:G2,'Nearest Neighbors'!B2:G2,0))), 'Nearest Neighbors'!B2))Successivamente, vogliamo inserire la classificazione effettiva e nota di ciascun punto di test in modo da poter determinare se il nostro modello aveva ragione o meno. Per questo utilizziamo un rapido VLOOKUP nella colonna C, partendo dalla cella C4 e trascinando verso il basso.
=VLOOKUP(A4, ‘Test Set’!$A$1:$F$46, 6, FALSE)Quindi imposteremo una formula nella colonna D per restituire un 1 se la previsione era errata o errata e uno 0 se la previsione era corretta. Inizierai nella cella D4 e trascinerai la formula verso il basso.
=IF(B4=C4, 0, 1)Infine calcoleremo il tasso di errore dividendo il numero di errori per il numero totale di punti dati, utilizzando questa formula nella cella B2. Per convenzione lo formatteremo come percentuale.
=SUM(D4:D48)/COUNT(D4:D48)Machine Learning con Excel : Esecuzione dell'algoritmo
Ora siamo pronti per eseguire il nostro algoritmo per diversi valori K. Poiché stiamo testando solo 6 valori, potremmo farlo a mano. Ma non sarebbe divertente e, cosa più importante, non scala. Prima di procedere , dovrai abilitare il componente aggiuntivo Risolutore per Excel seguendo le istruzioni in questo articolo.
Ora vai alla barra multifunzione Dati e fai clic sul pulsante Risolutore. Il pulsante del risolutore esegue automaticamente le prove e gli errori secondo le nostre istruzioni. Avrai una finestra di dialogo di parametri o istruzioni, che vorrai impostare come mostrato di seguito. Lo stiamo configurando in modo che cerchi di ridurre al minimo il tasso di errore durante il test di valori compresi tra 1 e 6, testando solo valori interi .

Excel girerà per un minuto e potresti vedere lampeggiare alcuni valori sullo schermo prima di visualizzare questa finestra di dialogo. È necessario fare clic su OK per mantenere la soluzione del risolutore.

Interpretazione del tasso di errore e della soluzione del risolutore
Molti algoritmi di ottimizzazione hanno più soluzioni a causa del fatto che i dati hanno più minimi o massimi. Questo è successo nel mio caso. Infatti, nel mio caso particolare, tutti i valori interi da 1 a 6 rappresentano i minimi con un tasso di errore di circa il 2%. Quindi, cosa facciamo ora?
Alcune cose mi passano per la testa. Innanzitutto, questo set di test non è molto buono. Il modello non ha ottenuto alcun vantaggio di ottimizzazione dal set di test e, in quanto tale, probabilmente rifarei il set di test e riprovare per vedere se ottengo risultati diversi. Considererei anche l'utilizzo di metodi di test più sofisticati come la convalida incrociata.
A un tasso di errore così basso nel mio set di test, comincio anche a preoccuparmi di un adattamento eccessivo. L'overfitting è un problema che si verifica nell'apprendimento automatico quando un modello è troppo adattato alle sfumature di un particolare set di dati di addestramento o test. Quando un modello è troppo adatto, non è così predittivo o efficace quando incontra nuovi dati in natura. Ovviamente, con un set di dati accademici come questo ci aspetteremmo che il nostro tasso di errore fosse piuttosto basso.
La considerazione successiva è quale valore scegliere se ho identificato diversi minimi. Sebbene il test non sia stato efficace in questo particolare esempio, in genere sceglierei il numero più basso di vicini che è al minimo per risparmiare risorse di calcolo. Il mio modello funzionerà più velocemente se deve considerare meno vicini. Non farà la differenza con un piccolo set di dati, ma decisioni come questa consentono di risparmiare risorse sostanziali su larga scala.
Conclusione sul Machine Learning con Excel
Complimenti! Hai imparato le basi dell'apprendimento automatico e implementato l'algoritmo KNN senza uscire dai confini di Excel. Ricorda che Excel è semplicemente uno strumento e che la parte importante è comprendere i concetti che fanno funzionare questo approccio. Comprendere i fondamenti ti aiuterà ad approfondire la scienza dei dati e l'apprendimento automatico e iniziare a sviluppare i tuoi modelli. Ora però il nostro consiglio è quello di iniziare a utilizzare Python o strumenti più scalabili di excel.






.png)

Commenti